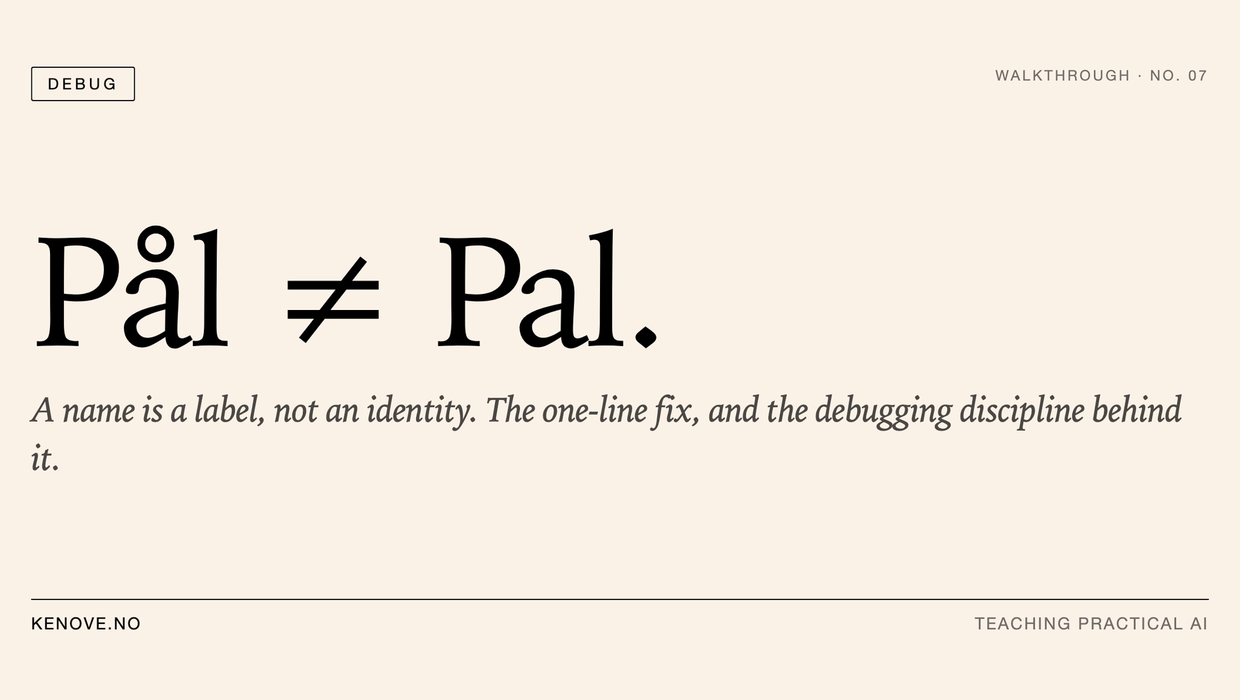
AI will write this exact feature for you in about a minute, and it will look completely correct. That is the trap. Here is a real one, from a system I actually run.
A patient sat down at a self-service kiosk to sign a consent form before their appointment. They typed their name and phone number. The kiosk threw an error:
Could not create patient.
Which made no sense. This person was already booked for that day. They were already in the system. So why was the kiosk trying to create them, and why did it fail?
That contradiction turned out to be the whole story.
What the kiosk is supposed to do
The kiosk's first job is simple: decide whether the person in front of it is someone we already know or someone new.
Already known: load their record, carry on.
New: create a record, carry on.
Get that one decision wrong and everything downstream is wrong too.
Before: identity by name, spelled perfectly
The original lookup matched a person on name and phone number together, and both had to line up exactly. The trap was in the name comparison. It was case-insensitive, but accent- and spelling-sensitive. So to the computer:
"Pal" ≠ "Pål"
"Anne-Marie" ≠ "Anne Marie"
"Jon Erik" ≠ "Jon" (a dropped middle name)Any of those tiny differences, and the kiosk concluded: I do not recognise this person. So it moved to plan B and tried to create a new record.
But the database has a sensible rule: no two patient records may share the same phone number. The person already existed, so their phone was already taken. The new record was rejected at the door. Result: "Could not create patient." A dead end.
The paradox, stated plainly
The kiosk failed to create the patient because the patient already existed. But it never realised they existed, because the name was not typed identically.
It was right and wrong at the same time. Right that this person is already here. Wrong to make a new one. The unique-phone rule was the only thing standing between this bug and a pile of duplicate records. The confusing error was the safety net doing its job, just with a bad label.
After: identity by phone, then email
The fix is a change to what counts as identity.
People mistype names. They drop accents, add middle names, abbreviate. A name is a label, not an identifier. A phone number, already enforced as unique, is the reliable fingerprint.
So the lookup now keys on phone number first, then email, and ignores the name entirely for matching:
Existing patient, name typed a little off: found by phone, record reused, no error.
Genuinely new person: created normally, exactly as before.
Safety net: if a create ever does collide (odd phone formatting, two near-simultaneous check-ins), instead of dead-ending it goes back and fetches the existing record.
One line of the philosophy changed: recognise people by the thing that is stable and unique, not by the thing they retype every visit.
A nice bonus: this is exactly how the online booking path already found patients. The kiosk was the odd one out. Now both speak the same language.
Before and after
Match on: exact name and phone, becomes phone, then email.
"Pål" vs "Pal": treated as two people, becomes the same person.
Existing patient, name slightly off: tries to create, gets rejected, errors out, becomes found and reused.
Brand-new patient: created, stays created, unchanged.
A duplicate slips through: hard error, dead end, becomes recovers and fetches the real record.
Consistent with online booking: no, becomes yes.
The twist: it looked like an infrastructure problem
Here is the part I almost got wrong.
The same morning, logins to a couple of internal apps were intermittently timing out. Easy to assume one cause. But the timeouts were a separate problem: the host was overloaded and starved of resources, and trimming what ran on it fixed that.
The "could not create patient" error was something else entirely, a logic flaw in the kiosk. The overload had only masked it. A slow, timed-out lookup can quietly read as "not found," which sends the code down the exact same doomed create-path.
Two failures wearing the same coat. The lazy move is to blame the loud, obvious thing (the server) and miss the quiet, real one (the logic). Read the actual error, not the nearest headline.
How I verified it, without guessing
I did not want to fix it and hope. So I reproduced both the old and new behaviour against the real system, signed in as a real user with real permissions:
1. Created a throwaway test patient, already in the system, name with an accent.
2. Old way (name plus phone, name typed without the accent): no match, would create, blocked by the unique-phone rule. Bug reproduced.
3. New way (look up by phone): found instantly, record reused.
4. New patient (fresh phone): created cleanly, no regression.
5. Duplicate on purpose: rejected, then the recovery step found the real record.
6. Deleted the test data. Zero residue.
Reproduce the bug and the fix before you call it done. If you cannot make the bug happen on demand, you do not understand it yet.
What to take from it
A name is a label, not an identity. Match people on something stable and unique (phone, email, an ID), never on free-typed text.
Make all your entry points agree. If one path finds users by phone and another by name, they will drift, and the odd one out is where the bug lives.
A confusing error can be a guardrail working. The unique-phone rule turned a silent duplicate-data disaster into a loud, fixable one.
Do not let the loud problem hide the quiet one. The obvious incident and the real bug are not always the same incident.
Here is the part that matters if you build with AI. Claude or Lovable will write the name-match lookup and the create-on-miss fallback in seconds, and it will read as correct, because it is correct, right up until two people named Pål and Pal walk in. What the assistant cannot do is decide what identity means for your system, or prove the fix actually holds. That judgment, and that verification, is the job. Small diff. Better system. Ship it.